![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)






























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)












































































































.png?#)

































_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)





































































































![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)






























































































































AI Model Achieves Record Performance in Image-Text Matching with Less Training Data
This is a Plain English Papers summary of a research paper called AI Model Achieves Record Performance in Image-Text Matching with Less Training Data. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview LLaVE develops embedding models from Large Language and Vision Models (LLMs) Introduces hardness-weighted contrastive learning to improve performance Outperforms specialized embedding models on 12 cross-modal retrieval benchmarks Enables zero-shot retrieval capabilities with minimal training data Balances easy and hard negative samples through dynamic weighting Plain English Explanation Today's AI systems struggle with tasks like finding the right image for a text description or vice versa. Imagine asking a computer to find a "cat playing with yarn" among thousands of images - this is called cross-modal retrieval. Current systems that handle these tasks are e... Click here to read the full summary of this paper
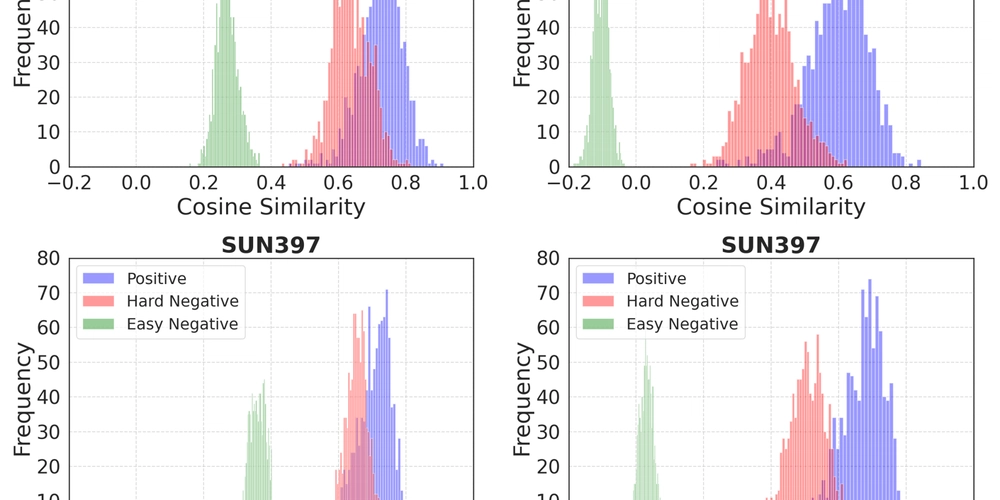
This is a Plain English Papers summary of a research paper called AI Model Achieves Record Performance in Image-Text Matching with Less Training Data. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- LLaVE develops embedding models from Large Language and Vision Models (LLMs)
- Introduces hardness-weighted contrastive learning to improve performance
- Outperforms specialized embedding models on 12 cross-modal retrieval benchmarks
- Enables zero-shot retrieval capabilities with minimal training data
- Balances easy and hard negative samples through dynamic weighting
Plain English Explanation
Today's AI systems struggle with tasks like finding the right image for a text description or vice versa. Imagine asking a computer to find a "cat playing with yarn" among thousands of images - this is called cross-modal retrieval.
Current systems that handle these tasks are e...